Your NextGen Managed Cloud Services Provider
Is the timing right to outsource your cloud services?
How can the cloud enable you to meet your business goals?
Thrive can help.
In today’s cloud era, businesses seek greater agility, scalability, and responsiveness to meet their objectives. However, there is no one-size-fits-all solution when it comes to selecting cloud platforms.
Thrive recognizes that a single cloud option may not be sufficient to meet your organizational needs. Instead, we embrace the idea of a multi-cloud environment, leveraging private, public, and software-as-a-service (SaaS) cloud platforms offering high performance, cost containment, enhanced cybersecurity, and flexibility. Our expert team of cloud consultants will work with you to design the solution that best fits your needs and budget.
Managed Public, Private & Hybrid Cloud Services and Solutions
Thrive offers a comprehensive range of managed cloud services that can be tailored to suit specific operational and budgetary requirements across both public and private cloud platforms. The goal is to seamlessly align your services with the diverse needs of your business. With a track record of delivering consistent cloud success, Thrive’s expert teams ensure that the essential elements of speed, security, and uptime are in place.
As a managed cloud service provider, we serve mid-market enterprises across various industries, including financial, healthcare, legal, insurance, life sciences/biotech, hospitality, manufacturing, government, and construction. Thrive’s expertise lies in assisting businesses in navigating the cloud landscape by providing guidance and support as trusted cloud consulting and service partners.

Best-in-Class Managed Cloud Solutions
Thrive’s hybrid cloud solutions are backed by a proven approach of delivering managed cloud services across public and private cloud platforms to maximize business performance. Our broad portfolio of cloud services can be customized to seamlessly match your operational and budget requirements
A Full Range of NextGen Cloud Solutions: Private, Public, or Hybrid
- Enterprise-class virtualization platforms, including HPE Greenlake Morpheus, Hyper-V, and Nutanix
- Managed IBM iSeries private cloud platforms built for the most demanding workloads
- Microsoft Azure public cloud offerings
- 24×7 monitoring, patching, management and support

Driving Cloud Application Performance, Anywhere 24x7
Are you responsible for a multi-cloud, SaaS-based environment? Thrive’s expert cloud engineering team is here to help design, build, and support the cloud solution that best meets your business needs. We assess your specific requirements, looking at performance, cost, security, and flexibility to determine the best cloud environments for your workloads.
In addition, our managed ThriveCloud complements private, public and software-as-a-service (SaaS) cloud offerings worldwide. Using the best in next gen cloud orchestration tools, Thrive delivers optimal visibility and control of both costs and workloads across your environment.
About ThriveCloud
As IT management continues to evolve, it’s no longer about expanding digital infrastructure operations from inside the traditional office walls to the cloud. Rather, it is about extending that experience to the cloud and beyond. ThriveCloud is an enterprise-class virtualization platform that offers the highest performance in security and efficiencies that enterprise-class business applications deserve.
The ThriveCloud platform offers the stability and power of enterprise-class Cloud infrastructure, customized to meet your exact business needs.
- 24×7 monitoring, management and support
- Virtual server hosting and management
- Cloud-based data protection
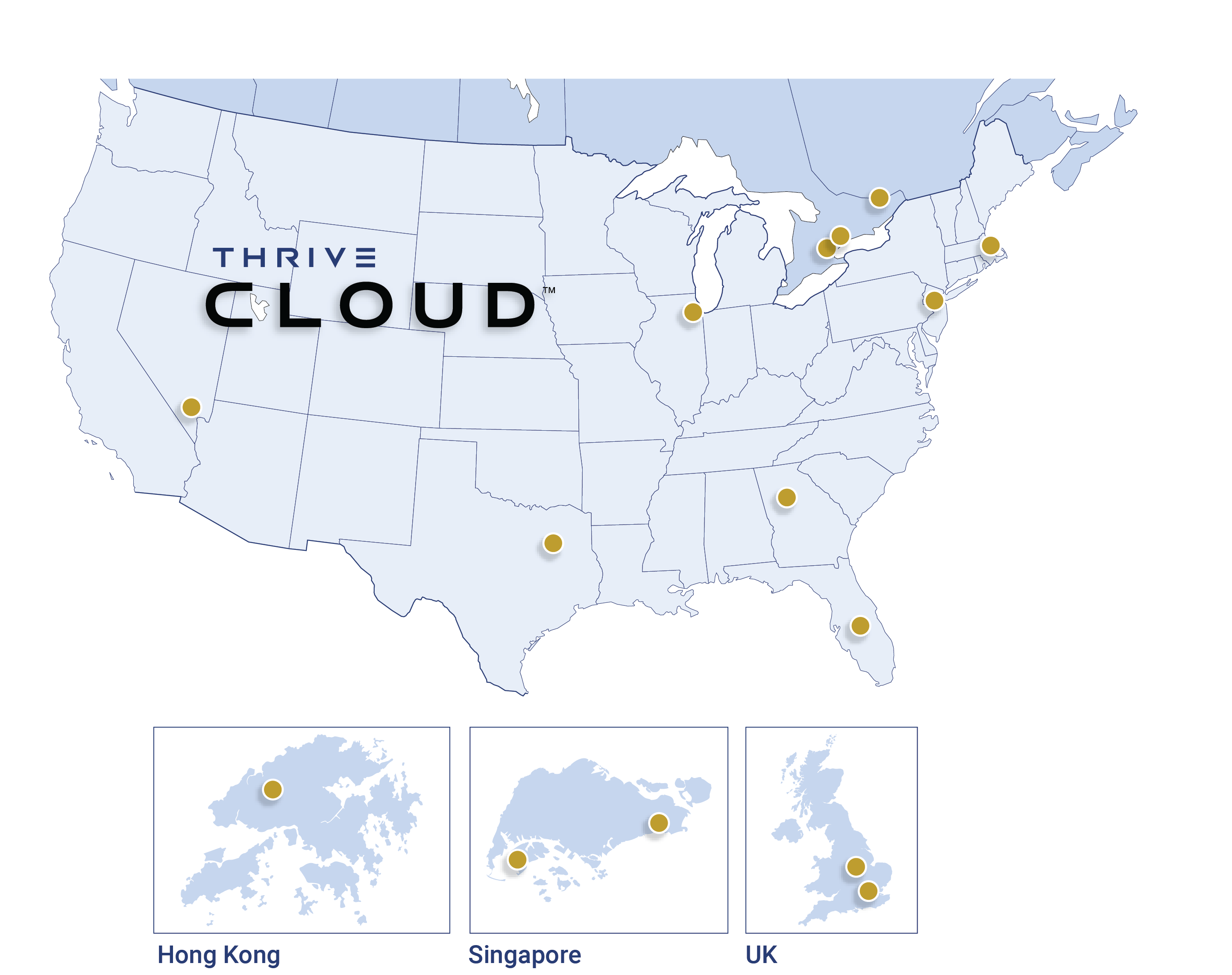
Secure, World-Class Data Centers
The ThriveCloud is housed in world-class SOC 2 Type II certified data centers around the world, including:
- Atlanta, GA
- Boston, MA
- Chicago, IL
- Dallas, TX
- Hong Kong
- Las Vegas, NV
- London, UK (2)
- Markham, Canada
- Montreal, Canada
- North Bergen, NJ
- Singapore (2)
- Toronto, Canada
- Winter Haven, FL

Driving Better Business Outcomes
“Thrive’s expertise means we can sleep easy knowing our systems are secure, and our team can work efficiently — no matter what challenges arise.”
– Richard Manoogian, Managing Director, Chief Compliance Officer, Northeast Investment Management, Inc.
Hear from Our Customers
Managed Microsoft Azure Cloud Services
Unlock the capabilities of the public Cloud with Thrive’s managed Microsoft Azure services.
Thrive’s specialized team of Cloud engineers and Azure experts can take infrastructure management to the next level and relieve your team of the 24×7 burden of managing workloads beyond the office walls. Thrive has the power to transform your business within Microsoft Azure.
- Optimal for applications that require hyper-scalability, high performance, and reliability
- Consumption-based billing offers flexibility for on-demand and seasonal workloads
Take Advantage of Hybrid Cloud Workloads
Leverage the technology and sophistication of a Hybrid Cloud environment with Thrive. We help boost your bottom line, productivity, and security with a reliable IT infrastructure customized to suit your business needs and optimize performance.
- Control Costs and Gain Value
- Eliminate the uncertainty and costly nature of infrastructure, hardware capital expenditures, and refresh cycles
- Streamline operating budgets and avoid expensive and cumbersome maintenance and support renewal agreements
- Gain More Flexibility
- Access your applications seamlessly and securely from anywhere
- Easily add or remove resources as your business requirements change
- Utilize multiple Cloud platforms to optimize performance and cost – all managed by Thrive’s expert team of Cloud engineers
- Improve Security and Resiliency
- Experience the highest levels of availability and performance with a fully redundant and resilient Cloud architecture
- Secure your data with NextGen Firewalls, Unified Threat Management platforms, MDR and Distributed Denial of Service (DDoS) detection and mitigation
Benefits of Managed Cloud Services
- Cost Savings A managed Cloud service provider saves your business capital or operational expenses needed to maintain your Cloud network infrastructure. In addition, you no longer have to hire and train people with the skill sets required to keep operating systems running to support your Cloud network.
- Automatic Updates Using a managed Cloud services provider, you no longer have to deal with trying to keep your Cloud infrastructure up to date. With Cloud technology constantly evolving, an MSP can keep your network updated and stay on top of advances and upgrades for your network infrastructure.
- Disaster Recovery Managed Cloud services ensure your business isn’t interrupted. If a disaster takes place, it’s important to safeguard and retrieve your data as soon as possible. MSPs can support your disaster recovery process and plans so that there is minimal downtime in the event of a disaster.
- Rapid Response A managed Cloud service provider gives you guaranteed round-the-clock support with a team of experts ready to respond to your network concerns or issues 24×7.
- Better Cloud and Network Security Keeping your network secure is a top priority when using the cloud, but security can be a complicated process. Managed service providers have the knowledge and experience to keep your Cloud network secure from unauthorized access.
- Centralized Control Managed Cloud service providers simply network administration and support with all of your controls in one location to easily make any changes or upgrades to your network.
- Flexible Scaling Managed Cloud service providers can keep pace with the increasing volume of web traffic and the proliferation of devices while managing the growth of cyber threats.
Frequently Asked Questions
How will moving to the cloud make our business more competitive?
Cloud adoption increases agility and enables faster deployment of applications and services. It also provides access to advanced tools and scalable infrastructure that support innovation.
What impact will cloud migration have on cost, flexibility, and performance?
Cloud can reduce capital expenditures and provide predictable operational costs. It also offers flexibility to scale resources and optimize performance for business-critical workloads.
How do you ensure our business-critical systems stay up and running?
We ensure business-critical systems stay up and running by implementing high-availability architectures, redundancy, and monitoring to minimize downtime and quickly resolve issues. Disaster recovery plans are integrated into all cloud deployments.
Can you help us optimize cloud spending as we scale?
Yes, Thrive continuously reviews usage, recommends rightsizing resources, and identifies cost-saving opportunities without compromising performance.
How do you reduce the risk of downtime or data loss in the cloud?
Through robust backup, disaster recovery, and replication strategies, combined with proactive monitoring and security controls, we ensure business continuity.
How can Thrive’s cloud services evolve as our strategy changes?
You can expand or shift workloads, adopt new tools, and integrate emerging technologies as your business grows. We offer managed virtualization for all major platforms, managed public cloud, and managed private cloud. Whatever cloud technology you need, we can help you design, migrate, and implement. We are partners with HPE and use their Morpheus Enterprise cloud platform for advanced management across many different platforms.
What are VMware alternatives?
Alternatives include Microsoft Hyper-V, Nutanix, Red Hat OpenShift, and cloud-native platforms like AWS EC2 or Azure Virtual Machines, depending on your organization’s needs and budget.
Our Latest Cloud Resources



Elevate your Business with Secure and Scalable Cloud Solutions
Customizable, secure, and reliable access to data and applications from any device, managed 24/7 by expert cloud engineers.
Ready to Speak with Our Experts?